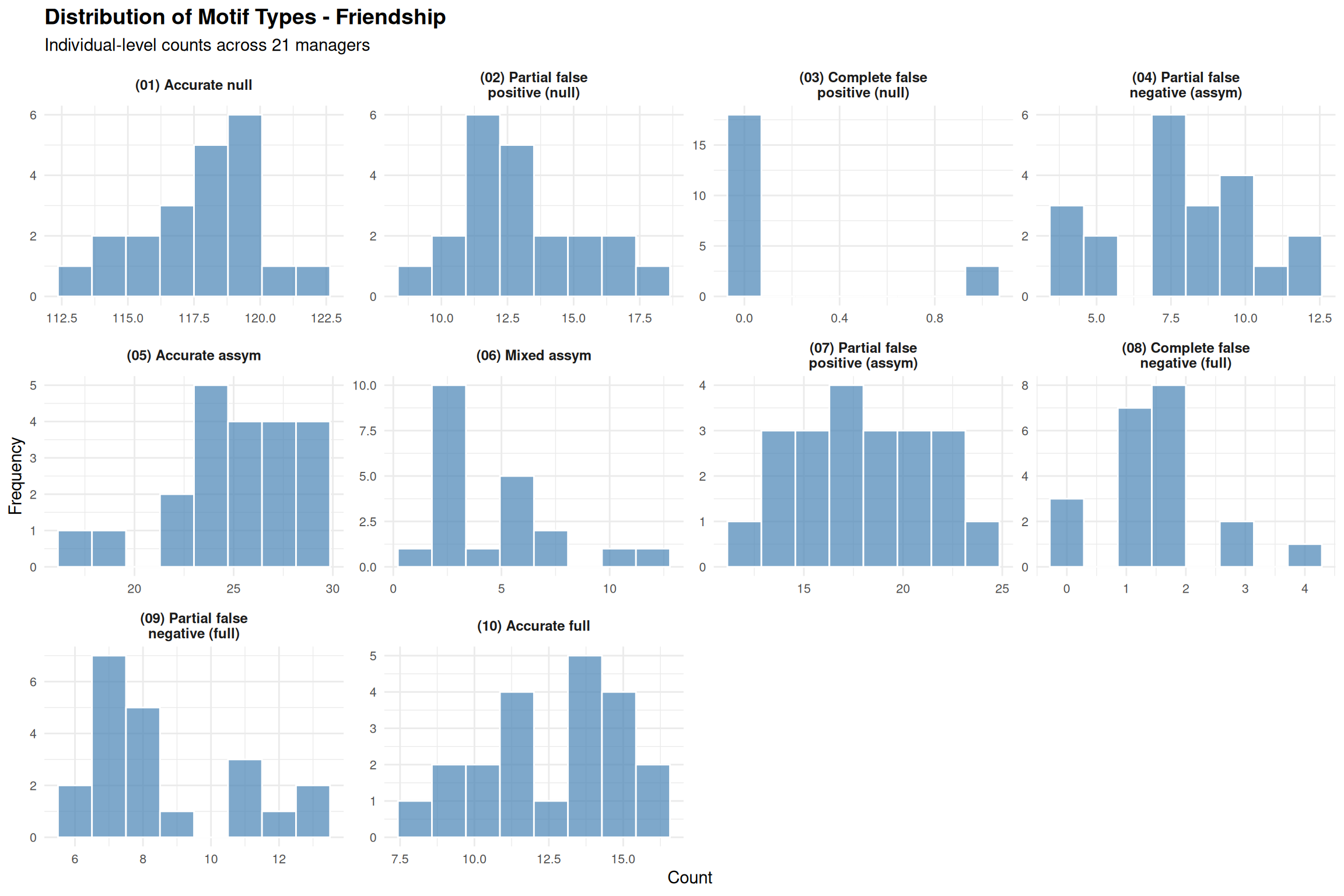
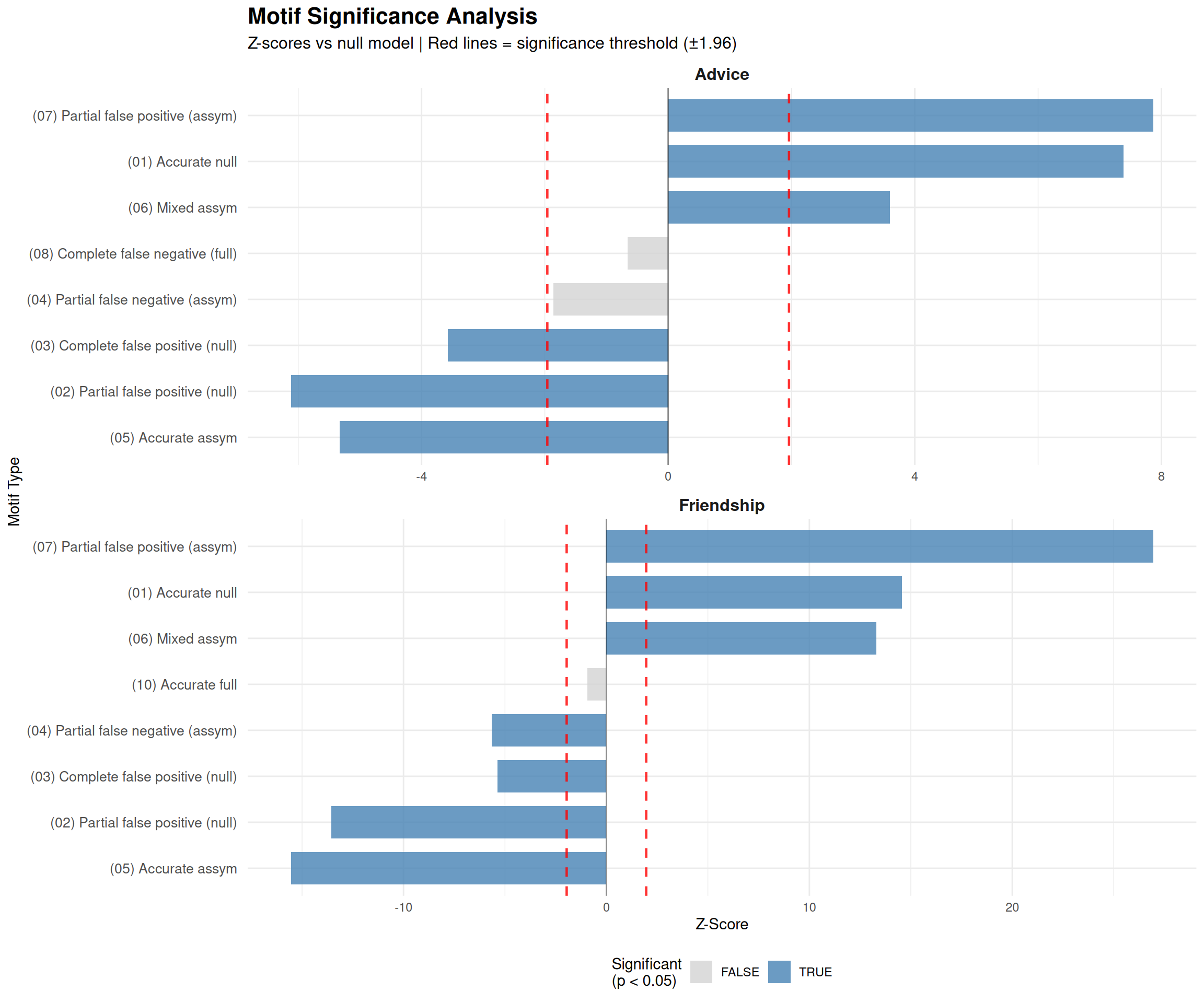
# Summary statistics
friend_sig_count <- sum(friendship_results$significant)
advice_sig_count <- sum(advice_results$significant)
friend_elevated <- sum(friendship_results$significant & friendship_results$z_score > 0)
advice_elevated <- sum(advice_results$significant & advice_results$z_score > 0)
cat("=== SUMMARY ===\n")
cat("Friendship network:", friend_sig_count, "significant motifs (",
friend_elevated, "elevated,", friend_sig_count - friend_elevated, "reduced)\n")
Friendship network: 7 significant motifs ( 3 elevated, 4 reduced)
cat("Advice network:", advice_sig_count, "significant motifs (",
advice_elevated, "elevated,", advice_sig_count - advice_elevated, "reduced)\n")
Advice network: 6 significant motifs ( 3 elevated, 3 reduced)
# Effect sizes
cat("\nEffect sizes (mean |Z-score|):\n")
Effect sizes (mean |Z-score|):
# Theoretical implications
cat("\n=== THEORETICAL IMPLICATIONS ===\n")
=== THEORETICAL IMPLICATIONS ===
if(friend_sig_count > advice_sig_count) {
cat("• Friendship networks show stronger systematic biases\n")
cat("• Consistent with balance schema and reciprocity assumptions\n")
} else {
cat("• Advice networks show stronger systematic biases\n")
cat("• May reflect hierarchy and expertise perception patterns\n")
}
• Friendship networks show stronger systematic biases
• Consistent with balance schema and reciprocity assumptions
cat("• Individual perception varies significantly from random baselines\n")
• Individual perception varies significantly from random baselines
cat("• Cognitive schemas systematically distort network perception\n")
• Cognitive schemas systematically distort network perception